Como a manutenção de arquivos no Figma virou um plugin.
Durante muito tempo trabalhei em arquivos de Figma que misturavam componentes internos, assets da comunidade e adaptações feitas em momentos diferentes do produto.
O problema raramente aparecia no começo. Ele surgia quando alguém precisava manter, reutilizar ou padronizar aquilo tudo sem desmontar o arquivo inteiro.
Era comum encontrar cores quase iguais espalhadas pelo projeto, componentes importados com nomenclaturas diferentes, estilos duplicados e padrões que mudavam dependendo da origem da interface.
Na maioria das vezes isso não acontecia por desorganização. O arquivo só estava acompanhando a velocidade do produto.
A comunidade do Figma ajudou muito a acelerar a construção de interface. Ficou mais fácil reutilizar componentes, adaptar referências e testar soluções rapidamente. Só que, depois de um tempo, o projeto começava a acumular decisões de origens diferentes:
- Bibliotecas externas;
- Assets reaproveitados;
- Componentes internos;
- Adaptações locais coexistindo no mesmo espaço.
E manter isso organizado manualmente começava a ficar custoso.
O problema da manutenção
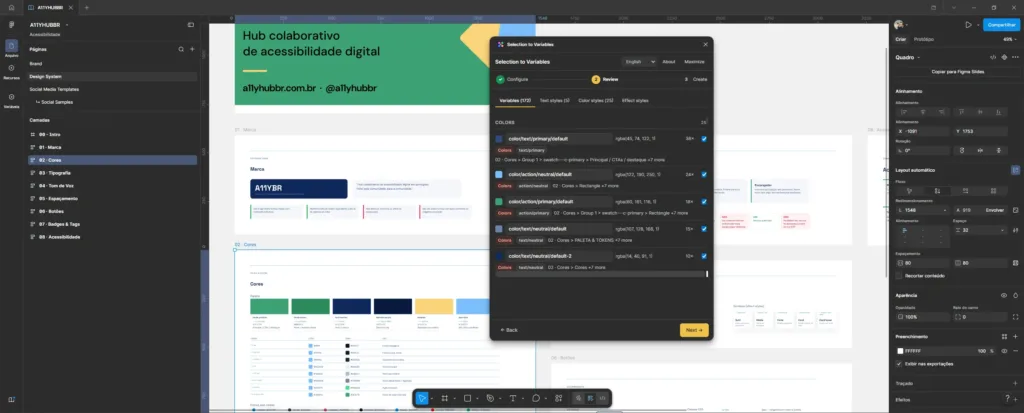
Quando o Figma lançou Variables, muita discussão apareceu em cima de cenários ideais: tokens organizados; nomenclaturas consistentes; bibliotecas maduras. Só que a maior parte dos arquivos reais não funciona assim.
Variáveis normalmente chegam quando o projeto já acumulou telas, ajustes rápidos e componentes adaptados várias vezes.
Transformar tudo isso manualmente em algo reutilizável cansa… Você seleciona um elemento, cria variável, nomeia, agrupa e repete o processo dezenas de vezes.
Em arquivos grandes, isso deixa de ser organização estrutural, vira manutenção operacional — e foi tentando reduzir esse atrito que comecei a experimentar automações dentro do Figma.
Tentando reduzir atrito
A ideia era relativamente simples:
Transformar propriedades recorrentes em variáveis reutilizáveis sem precisar reorganizar o arquivo inteiro.
O objetivo era facilitar a manutenção em projetos que já estavam vivos, principalmente em cenários onde:
- Componentes externos já fazem parte do fluxo;
- Existem múltiplos padrões convivendo no mesmo arquivo;
- Parte da interface foi construída em momentos diferentes;
- Padronizar tudo manualmente custa tempo demais;
No começo, usei IA como apoio para estruturar o código inicial do experimento. O Claude ajudou bastante a acelerar as primeiras versões. Em poucas horas eu já conseguia testar comportamento dentro do Figma, mas os problemas mais difíceis apareceram depois.
IA acelera execução, mas jamais o entendimento completo
Gerar código rapidamente não significa entender profundamente o contexto onde ele roda. A parte mais trabalhosa do processo acabou sendo:
- Validar comportamento em arquivos reais;
- Lidar com componentes importados;
- Revisar agrupamentos;
- Entender limitações da Plugin API;
- Ajustar inconsistências entre padrões diferentes.
A IA ajudava muito quando eu já entendia o problema. Quando eu não entendia, ela acelerava respostas erradas com bastante eficiência, e isso ficou ainda mais claro depois da aprovação do plugin no Figma.
O maldito erro que a IA não resolveu
Depois da publicação, apareceu um erro importante. A parte da lógica estava usando uma API pública em um contexto onde o correto seria trabalhar com acesso privado. O comportamento parecia funcionar parcialmente, mas quebrava em cenários específicos.
Passei um tempo tentando resolver isso usando IA e não consegui sair do lugar, mas a solução apareceu numa conversa com um desenvolvedor que identificou rapidamente onde estava o problema estrutural.
Depois disso, consegui voltar para IA já entendendo o contexto técnico necessário para ajustar o código corretamente.
Provavelmente o meu problema por não saber nada de programação foi agravado no cenário, mas esse processo mudou bastante minha visão sobre IA aplicada ao desenvolvimento.
Hoje vejo IA muito mais como acelerador de execução. O impacto da IA para o desenvolvimento é o mesmo que tenho para o design; é uma “simples” ferramenta.
Designers provavelmente vão criar mais ferramentas
Outra coisa que me surpreendeu foi perceber que provavelmente designers têm várias ideias de ferramentas (eu, pelo menos, tenho), mas nunca tentam construir nada porque enxergam desenvolvimento como algo distante da própria área, só que a barreira de entrada mudou bastante.
Hoje já é possível validar pequenas automações, criar plugins simples e experimentar tooling sem precisar atuar como engenheiro fulltime.
Ao mesmo tempo, isso também deixou mais evidente uma diferença importante:
Conseguir gerar código não significa necessariamente conseguir construir produto.
Mesmo um plugin pequeno envolve:
- Fluxo;
- Contexto;
- Manutenção;
- Comportamento previsível;
- Tratamento de erro;
- Documentação;
- Revisão;
- Testes em cenários reais.
A parte mais difícil raramente está no “código funcionar”; ela aparece quando a ferramenta encontra o caos dos arquivos reais.
Arquivos reais raramente seguem estruturas perfeitas
Talvez esse tenha sido o principal aprendizado do processo inteiro: os arquivos reais do Figma raramente seguem estruturas idênticas, eles acumulam referências externas, “adaptações rápidas”, componentes reaproveitados e decisões temporárias que acabam ficando permanentes, e talvez o desafio não seja impedir isso.
Talvez seja conseguir manter esses arquivos utilizáveis ao longo do tempo.
Referências e links
Durante o processo, usei bastante a documentação oficial do Figma para entender o comportamento da Plugin API, permissões e limitações da plataforma:
- Documentação da API do plugin do Figma
- Exemplo de plugins do Figma (Repositório do Github)
- Documentação do Figma AI
Também deixei o experimento publicado na comunidade do Figma. Se quiser testar em arquivos reais, entender melhor o fluxo ou simplesmente “quebrar” a ferramenta, adoraria receber feedback da comunidade.
Quer conversar sobre este conteúdo?
Os comentários estão disponíveis aqui, mas se você não quiser escrever nessa seção, poderá compartilhar sua opinião através do e-mail ou no Bluesky.